What is Data Structure?
Data structures are fundamental concepts in computer science that define efficient ways to organise, store, and manipulate data in computer programs. They provide systematic methods to manage and operate on data, enabling optimal utilisation of memory and performance. Key aspects include linear data structures like arrays, linked lists, stacks, and queues that store elements sequentially, and non-linear structures like trees, graphs, and hash tables for hierarchical and interconnected data relationships. Choosing the right data structure is crucial, considering factors like operations, time/space complexity, memory constraints, data characteristics, and access patterns. Understanding different data structures, their operations, strengths, and limitations is essential for writing efficient, optimised code and developing high-performance, scalable software applications.
Date Posted: Thu 13th Jun, 2024

In computer science, a data structure is a way of organising and storing data in a computer's memory so that it can be used efficiently. It defines how the data is stored, accessed, and manipulated within a program. Data structures are fundamental building blocks in programming, as they allow us to manage and operate on data effectively.
- Organising and storing data in computer's memory: The primary purpose of a data structure is to provide a systematic and efficient way to organise and store data in a computer's memory. Memory is a limited resource, and data structures help in utilising it effectively by arranging data in a specific layout or format.
- Efficient use of data: Data structures are designed to ensure that the data stored in memory can be used efficiently. They define the rules and mechanisms for accessing, retrieving, modifying, and manipulating the stored data in an optimized manner.
- Defining data storage and operations: A data structure not only specifies how the data is stored but also defines the operations that can be performed on the data. It determines the set of operations available for inserting, deleting, searching, sorting, and traversing the data elements stored within the structure.
- Within a program: Data structures are used within computer programs to manage and operate on data. They are an integral part of programming and are responsible for the efficient storage, manipulation, and retrieval of data required by various algorithms and computations within a program.
- Fundamental building blocks: Data structures are considered fundamental building blocks in programming because they form the foundation for designing and implementing efficient algorithms and software systems. Without proper data structures, it would be challenging to write efficient and scalable programs that can handle large amounts of data effectively.
- Managing and operating on data effectively: By using appropriate data structures, programmers can manage and operate on data in an effective manner. Data structures provide a structured and organized way to store and access data, enabling efficient data processing, retrieval, and manipulation operations, which are crucial for developing high-performance and robust software applications.
The statement highlights that data structures are essential concepts in computer science that define how data is organized, stored, accessed, and manipulated within a program's memory. They provide a systematic and efficient way to manage and operate on data, ensuring optimal utilization of memory resources and enabling the development of efficient algorithms and software systems.
Why Data Structures?
Data structures play a crucial role in software development for several reasons:
1. Efficient Data Organisation:
- Data structures provide a systematic and organized way to store and manage data, which is crucial for efficient data processing and retrieval.
- Without a proper data structure, data would be stored in an unorganized manner, making it difficult to access, modify, or manipulate the data efficiently.
- By using appropriate data structures, programmers can store and arrange data in a logical and structured way, enabling faster access, insertion, deletion, and other operations on the data.
- This organised storage of data is essential for efficient data processing and retrieval, as it reduces the time and computational resources required to perform various operations on the data.
2. Algorithm Design:
- The choice of an appropriate data structure can significantly impact the performance and efficiency of algorithms.
- Different data structures are suitable for different types of operations and algorithms, and using the right data structure can make a significant difference in the execution time and resource utilization of an algorithm.
- For example, if an algorithm requires frequent searching operations, using a data structure like a binary search tree or a hash table would be more efficient than using a linear data structure like an array or a linked list.
- Similarly, if an algorithm requires frequent insertion or deletion operations at the beginning or end of a data structure, a linked list would be more efficient than an array.
- By carefully selecting the appropriate data structure for a particular algorithm or problem, programmers can optimise the algorithm's performance, reducing its time and space complexity.
3. Memory Management:
- Data structures help in efficient utilisation of computer memory by storing data in an optimised manner, reducing memory wastage and enabling better memory management.
- Different data structures have varying memory requirements and memory usage patterns, and choosing the right data structure can help minimize memory wastage and optimise memory utilisation.
- For example, dynamic data structures like linked lists can allocate and deallocate memory as needed, avoiding the need to pre-allocate large contiguous blocks of memory, as is the case with arrays.
- By using memory-efficient data structures, programmers can ensure that their applications use memory resources effectively, reducing the risk of memory leaks or running out of memory.
- Efficient memory management is particularly important in resource-constrained environments, such as embedded systems or mobile devices, where memory is limited.
4. Code Reusability:
- Many data structures are implemented as abstract data types (ADTs), which provide a well-defined interface for common operations. This promotes code reusability and modular programming.
- An ADT defines the data structure and the set of operations that can be performed on the data, without specifying the implementation details.
- By using ADTs, programmers can write code that interacts with the data structure through its interface, without needing to know the underlying implementation details.
- This promotes code reusability, as the same ADT implementation can be used across multiple parts of a program or across different programs, as long as the interface remains consistent.
- Additionally, ADTs support modular programming, where different components of a program can be developed and tested independently, as long as they adhere to the ADT's interface.
- This separation of concerns between the interface and implementation also facilitates code maintenance and evolution, as the implementation details of a data structure can be modified without affecting the code that uses the ADT interface.
Data Structures play a crucial role in software development by enabling efficient data organisation, optimising algorithm performance, managing memory resources effectively, and promoting code reusability and modular programming through the use of abstract data types.
Common Data Structure Operations
Most data structures support a set of common operations, such as:
- Insertion: Adding a new data item to the data structure.
- Deletion: Removing an existing data item from the data structure.
- Search: Finding a specific data item within the data structure.
- Traversal: Accessing or processing all the data items in the data structure in a specific order.
- Sorting: Rearranging the data items in a specific order (e.g., ascending or descending).
- Merging: Combining two or more ordered data structures into a single ordered data structure.
Types of Data Structures
Data structures can be broadly classified into two categories: linear data structures and non-linear data structures. This classification is based on the way data elements are organised and stored within the structure.
1. Linear Data Structures:
Linear data structures store data elements in a sequential or linear order. This means that the elements are arranged in a sequence, and each element has a successor and/or a predecessor, except for the first and last elements. Linear data structures are further divided into the following types:
1. Arrays:
- An array is a collection of elements of the same data type stored in contiguous memory locations.
- Each element in an array is identified by its index, which represents its position within the array.
- Arrays provide constant-time access to elements by index, but inserting or deleting elements in the middle of an array can be inefficient as it requires shifting the remaining elements.

Arrays in Java are fixed-size data structures, meaning their size cannot be changed after they are created. However, Java provides other dynamic array implementations like ArrayList and Vector that can resize themselves as needed.
Arrays are efficient for random access of elements (accessing elements by their indices) but can be inefficient for insertions and deletions at arbitrary positions, as these operations require shifting the remaining elements in the array.
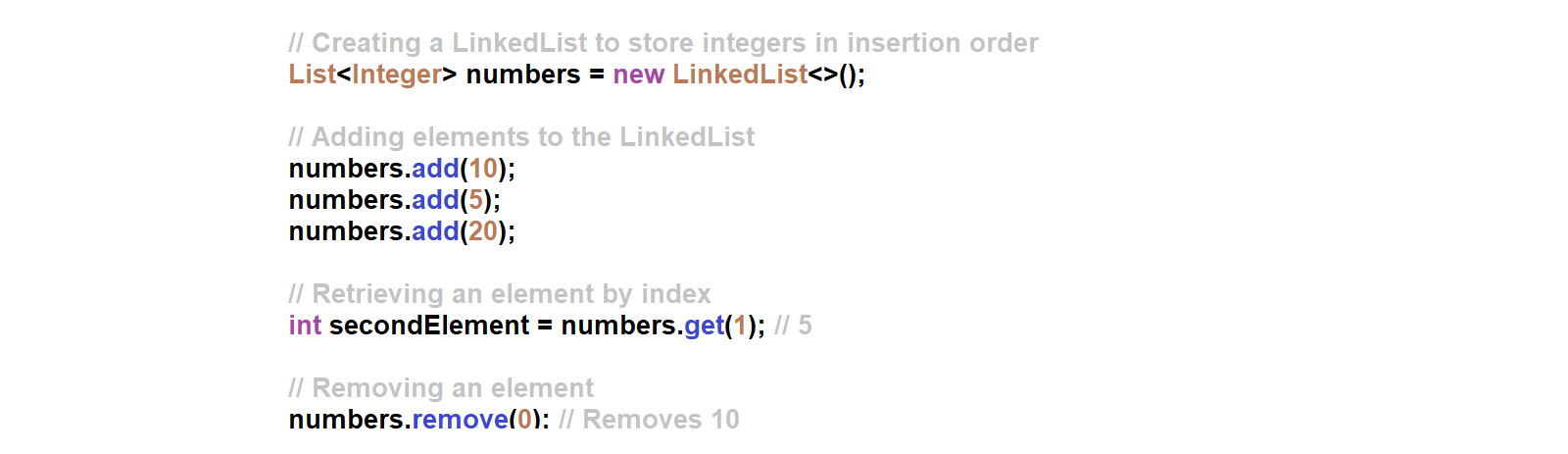
2. Linked Lists:
- A linked list is a collection of nodes, where each node contains data and a reference (link) to the next node in the sequence.
- The nodes are not necessarily stored in contiguous memory locations, allowing dynamic memory allocation and deallocation.
- Linked lists provide efficient insertion and deletion operations but have linear-time access to elements since they must be traversed sequentially.

In this example, we perform various operations on a LinkedList of Strings:
- Creating a LinkedList: We create an empty LinkedList of Strings using the new LinkedList<>() constructor.
- Adding elements: We add elements to the LinkedList using the add() method. Elements can be added at the end of the list or at a specific index.
- Removing elements: We remove an element from the LinkedList using the remove() method, which can take either an object or an index as an argument.
- Accessing elements: We access elements in the LinkedList using the get() method, which takes an index as an argument.
- Iterating over the LinkedList: We iterate over the elements of the LinkedList using an enhanced for loop and an iterator.
- Checking for elements: We check if the LinkedList contains a specific element using the contains() method.
- Getting the size: We get the size (number of elements) of the LinkedList using the size() method.
Unlike arrays, LinkedLists are dynamic data structures that can resize themselves as needed. They are well-suited for frequent insertions and deletions at arbitrary positions, as these operations do not require shifting elements in memory.
However, LinkedLists have a disadvantage when it comes to random access of elements, as accessing an element by index requires traversing the list from the beginning or the end, leading to a linear-time operation.
Both arrays and LinkedLists are linear data structures, but they have different strengths and weaknesses. Arrays are efficient for random access but inefficient for insertions and deletions at arbitrary positions, while LinkedLists are efficient for insertions and deletions but inefficient for random access.
3. Stacks: A linear data structure that follows the Last-In-First-Out (LIFO) principle, where insertion and deletion operations occur at the same end, called the top.
- A stack is a linear data structure that follows the Last-In-First-Out (LIFO) principle.
- Insertion and deletion operations occur at the same end, called the top of the stack.
- Stacks are commonly used for function call management, expression evaluation, and backtracking algorithms.
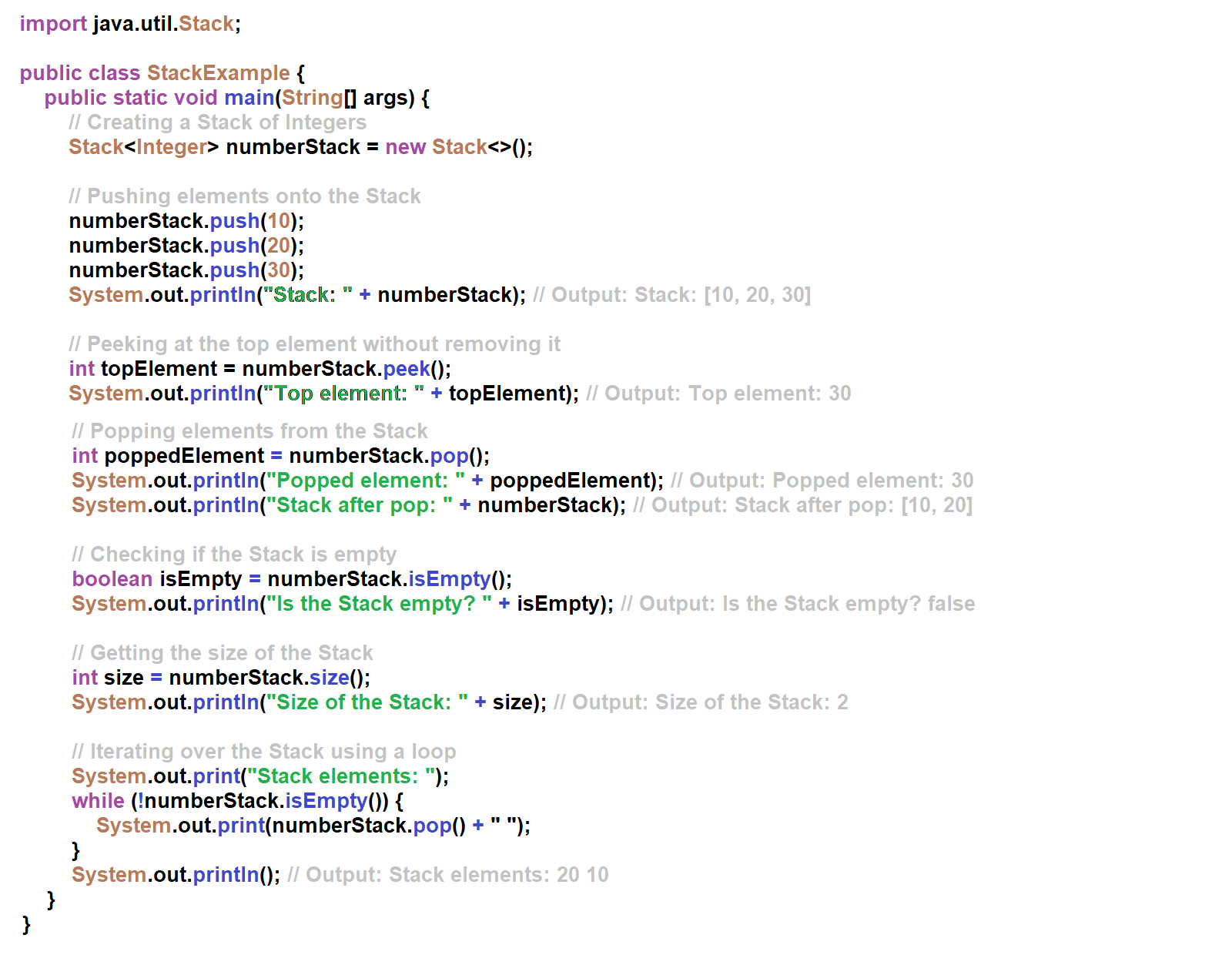
In this example, we perform various operations on a Stack of Integers:
- Creating a Stack: We create an empty Stack of Integers using the new Stack<>() constructor.
- Pushing elements: We push elements onto the top of the Stack using the push() method.
- Peeking at the top element: We retrieve the top element of the Stack without removing it using the peek() method.
- Popping elements: We remove and retrieve the top element from the Stack using the pop() method.
- Checking if the Stack is empty: We check if the Stack is empty using the isEmpty() method.
- Getting the size: We get the size (number of elements) of the Stack using the size() method.
- Iterating over the Stack: We iterate over the elements of the Stack by repeatedly popping elements until the Stack is empty.
Stacks are linear data structures that follow the Last-In-First-Out (LIFO) principle. New elements are added and removed from the same end, called the top of the stack. Stacks are commonly used for implementing function call stacks, expression evaluation, backtracking algorithms, and other scenarios where a LIFO order is needed.
The main operations on a Stack are push() (to add an element to the top), pop() (to remove and retrieve the top element), peek() (to retrieve the top element without removing it), and isEmpty() (to check if the Stack is empty).
Stacks can be implemented using arrays or linked lists as the underlying data structure. The Java Stack class is a legacy class that extends the Vector class, which is a dynamic array implementation. However, in modern Java, it is recommended to use the Deque interface (with implementations like ArrayDeque or LinkedList) for stack operations, as it provides a more flexible and efficient implementation.
4. Queues: A linear data structure that follows the First-In-First-Out (FIFO) principle, where insertion occurs at the rear end, and deletion occurs at the front end.
- A queue is a linear data structure that follows the First-In-First-Out (FIFO) principle.
- Insertion (enqueue) occurs at the rear end, and deletion (dequeue) occurs at the front end.
- Queues are commonly used for scheduling processes, handling interrupts, and implementing breadth-first search algorithms.

In this example, we perform various operations on a Queue of Strings:
- Creating a Queue: We create an empty Queue of Strings using the new LinkedList<>() constructor. In Java, the LinkedList class implements the Queue interface, so it can be used as a Queue data structure.
- Enqueuing elements: We add elements to the rear of the Queue using the offer() method.
- Peeking at the front element: We retrieve the front element of the Queue without removing it using the peek() method.
- Dequeuing elements: We remove and retrieve the front element from the Queue using the poll() method.
- Checking if the Queue is empty: We check if the Queue is empty using the isEmpty() method.
- Getting the size: We get the size (number of elements) of the Queue using the size() method.
- Iterating over the Queue: We iterate over the elements of the Queue by repeatedly dequeuing elements until the Queue is empty.
Queues are linear data structures that follow the First-In-First-Out (FIFO) principle. New elements are added at the rear of the queue, and elements are removed from the front of the queue. Queues are commonly used for implementing scheduling algorithms, handling asynchronous events, and other scenarios where a FIFO order is required.
The main operations on a Queue are offer() (to add an element at the rear), poll() (to remove and retrieve the front element), peek() (to retrieve the front element without removing it), and isEmpty() (to check if the Queue is empty).
In Java, the Queue interface provides a contract for queue operations, and various implementations are available, such as LinkedList, ArrayDeque, and PriorityQueue. The choice of implementation depends on the specific requirements of the program, such as thread-safety, performance characteristics, and priority-based ordering.
2. Non-linear Data Structures:
Non-linear data structures do not store data elements in a sequential or linear order. Instead, they organise data in a hierarchical or graph-like structure, where elements can have multiple connections or relationships. Examples of non-linear data structures include:
1. Trees: A hierarchical data structure consisting of nodes connected by edges, where each node can have one or more child nodes.
- A tree is a hierarchical data structure consisting of nodes connected by edges.
- Each node can have one or more child nodes, except for the root node, which has no parent.
- Trees are widely used for representing hierarchical data, such as file systems, decision trees, and binary search trees.
2. Graphs: A collection of nodes (vertices) and edges that connect pairs of nodes, representing relationships or connections between the nodes.
- A graph is a collection of nodes (vertices) and edges that connect pairs of nodes, representing relationships or connections between the nodes.
- Graphs can be directed (edges have a specific direction) or undirected (edges have no direction).
- Graphs are used to represent and analyse networks, social connections, and various optimization problems.
3. Hash Tables: A data structure that uses a hash function to map keys to values, providing constant-time average-case complexity for insertion, deletion, and search operations.
- A hash table is a data structure that uses a hash function to map keys to values.
- The hash function converts the key into an index (hash code) within an array (hash table).
- Hash tables provide constant-time average-case complexity for insertion, deletion, and search operations, making them efficient for fast data retrieval and storage.
The classification of data structures into linear and non-linear structures helps in understanding and selecting the appropriate data structure based on the specific requirements of a problem or application. Linear data structures are suitable for sequential data access and processing, while non-linear data structures are better suited for representing hierarchical or interconnected data relationships.
Choosing a Data Structure
Selecting the appropriate data structure for a particular problem or application is crucial for efficient problem-solving and algorithm design.
The choice of data structure is critical because it determines the efficiency and performance of the software application. An ill-chosen data structure can make the program slower, consume more memory, and in some cases, can even make the program crash when the data gets too large.
The choice of choosing a data structure depends on various factors, such as:
1. Type of operations: The operations that need to be performed on the data (e.g., insertion, deletion, search, traversal).
- The choice of a data structure heavily depends on the types of operations that need to be performed on the data.
- Different data structures are designed to efficiently support specific operations.
- For example, if the primary operations are insertions and deletions at the beginning or end of the data structure, a linked list would be a suitable choice.
- If frequent searches are required, a binary search tree or a hash table would be more efficient.
- If random access to elements is needed, an array might be the best choice.
- By analysing the operations required for a particular problem, you can identify the data structure that provides the most efficient implementation for those operations.
2. Time and space complexity: The time and space requirements of different operations for different data structures.
- Different data structures have varying time and space complexities for different operations.
- Time complexity refers to the amount of time an algorithm or operation takes to complete as the input size grows, while space complexity refers to the amount of memory required by the algorithm or data structure.
- For example, searching in an unsorted array has a time complexity of O(n), while searching in a sorted array using binary search has a time complexity of O(log n), which is more efficient for large datasets.
- Similarly, the space complexity of an array is fixed and determined at the time of its creation, while the space complexity of a linked list can grow dynamically as new nodes are added.
- Understanding the time and space complexities of different data structures for various operations helps in selecting the most efficient data structure for a given problem, considering the trade-off between time and space requirements.
3. Memory constraints: The amount of memory available and the memory usage of different data structures.
- The amount of available memory can play a significant role in choosing a data structure.
- Some data structures, such as arrays, require a contiguous block of memory, which can be limited in certain environments, like embedded systems or resource-constrained devices.
- Other data structures, like linked lists or hash tables, can dynamically allocate and deallocate memory as needed, making them more memory-efficient in certain scenarios.
- Memory constraints must be considered, especially when working with large datasets or in memory-constrained environments, to ensure that the chosen data structure does not exhaust the available memory resources.
4. Data characteristics: The nature of the data being stored (e.g., sorted, unsorted, dynamic, static).
- The nature of the data being stored can influence the choice of an appropriate data structure.
- If the data is sorted or needs to be maintained in a sorted order, data structures like binary search trees or self-balancing trees (e.g., AVL trees, Red-Black trees) might be more suitable.
- If the data is static and not subject to frequent modifications, an array might be a good choice due to its efficient random access capabilities.
- If the data is dynamic and subject to frequent insertions and deletions, a linked list or a dynamic array (e.g., ArrayList, Vector) might be more appropriate.
- Understanding the characteristics of the data, such as its size, structure, and expected changes, helps in selecting the most suitable data structure.
5. Access patterns: The way data needs to be accessed (e.g., sequential, random, or based on specific criteria).
- The way data needs to be accessed can significantly influence the choice of a data structure.
- If the data needs to be accessed sequentially, linear data structures like arrays or linked lists are appropriate choices.
- If random access to data elements is required, arrays or hash tables might be better options.
- If the data needs to be accessed based on specific criteria (e.g., searching for elements within a specific range), data structures like binary search trees or skip lists can be more efficient.
- Understanding the access patterns of the data and the specific requirements of the problem helps in selecting the data structure that provides the most efficient access to the data.
The choice of an appropriate data structure is crucial because it directly impacts the efficiency, performance, and scalability of the software application. Selecting the right data structure involves carefully considering the various factors mentioned above and understanding the strengths and weaknesses of different data structures for different scenarios. This understanding is essential for writing efficient and optimized code that can handle large datasets and complex problems effectively.
Here are some examples of choosing the appropriate data structure in Java based on different scenarios:
Scenario 1: Storing and retrieving unique elements. If you need to store a collection of unique elements and perform frequent lookups, insertions, and deletions, a HashSet would be an appropriate choice.

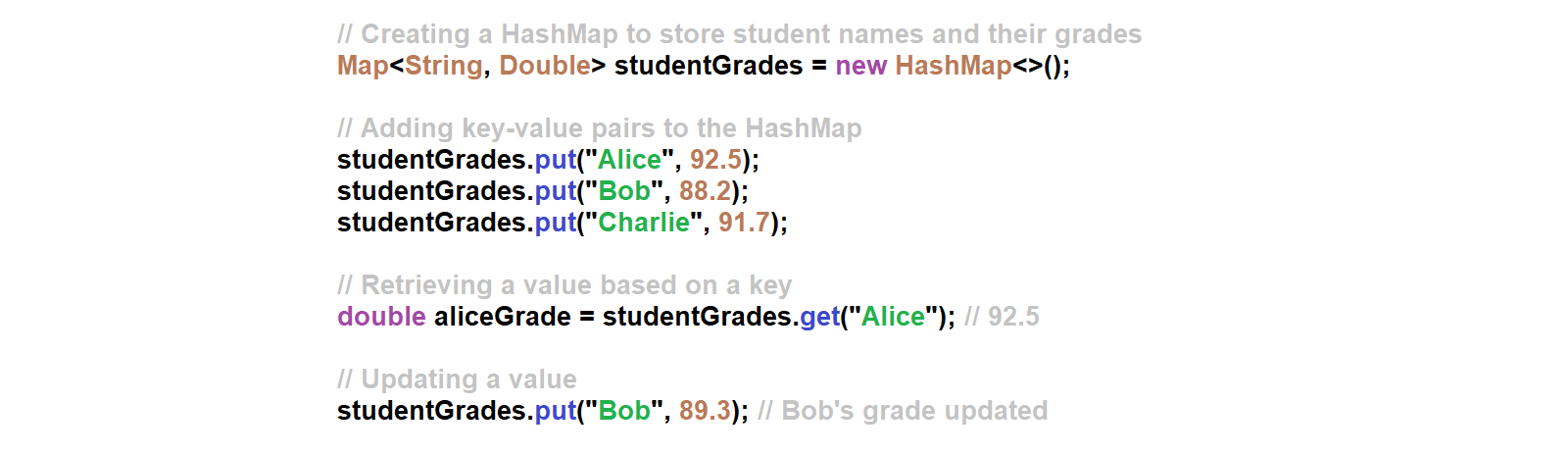
Scenario 2: Storing and retrieving key-value pairs. If you need to store key-value pairs and perform frequent lookups based on keys, a HashMap is an efficient choice.
Scenario 3: Storing and retrieving elements in a specific order. If you need to store elements in a specific order (e.g., insertion order or sorted order) and perform frequent insertions and deletions, a LinkedList would be a suitable choice.
Scenario 4: Storing and retrieving sorted elements. If you need to store elements in a sorted order and perform frequent searches, insertions, and deletions, a TreeSet would be an appropriate choice.

Scenario 5: Storing and retrieving elements based on priority. If you need to store elements based on a priority order and perform frequent insertions and removals of the highest or lowest priority element, a PriorityQueue would be a suitable choice.

These example scenarios demonstrate how different data structures in Java can be chosen based on the specific requirements of the problem, such as the need for unique elements, key-value pairs, ordered elements, sorted elements, or priority-based elements, as well as the expected operations (insertions, deletions, lookups, etc.). By carefully analysing the problem requirements and understanding the strengths and weaknesses of different data structures, you can choose the most appropriate data structure to ensure efficient and optimised code.
Data structures are fundamental concepts in computer science that provide efficient ways to organise, store, and manipulate data in computer programs. Understanding different data structures, their operations, and their time and space complexities is essential for writing efficient and optimised code. Choosing the right data structure for a particular problem can significantly impact the performance and scalability of software applications.
Same Category
General Category
- Artificial General Intelligence (AGI) 8
- Robotics 5
- Algorithms & Data Structures 4
- Tech Business World 4
Sign Up to New Blog Post Alert