Understanding Machine Learning: Principles and Functionality
Unlock insights and refine your understanding of essential concepts in machine learning with expertly crafted reframed content. Dive into diverse topics such as algorithm selection, programming language preferences, enterprise applications, and prerequisite knowledge, all tailored to enhance your comprehension and mastery of this dynamic field.
Date Posted: Fri 17th May, 2024

Machine learning, a fascinating branch of Artificial Intelligence, is integrated into many aspects of our daily lives. By harnessing the power of data, machine learning enables new capabilities, like Facebook recommending articles in your feed. This remarkable technology allows computer systems to learn and enhance their performance by creating programs that can automatically process data and carry out tasks through predictions and detections.
As more data is input into a machine, the algorithms refine their learning, leading to better results. For instance, when you ask Alexa to play your favourite music station on Amazon Echo, she will choose the station you play most frequently. You can further personalise your listening experience by instructing Alexa to skip songs, adjust the volume, and execute numerous other commands. The rapid advancement of Artificial Intelligence and Machine Learning powers these innovations.
Machine learning is a fundamental sub-field of Artificial Intelligence (AI). Unlike traditional programming, ML applications learn from experience (or more precisely, from data) similar to how humans do. When introduced to new data, these applications can autonomously learn, evolve, and improve. Essentially, machine learning enables computers to discover valuable insights without explicit instructions, utilising algorithms that iteratively learn from data.
While the concept of machine learning has historical roots (consider the World War II Enigma Machine, for example), the modern practice of automating complex mathematical computations on large datasets has gained significant traction only in recent years.
At its core, machine learning is characterised by its ability to adapt to new data independently and iteratively. By learning from past computations and transactions, these applications employ pattern recognition to generate reliable and informed results.
What is the Mechanism behind Machine Learning?
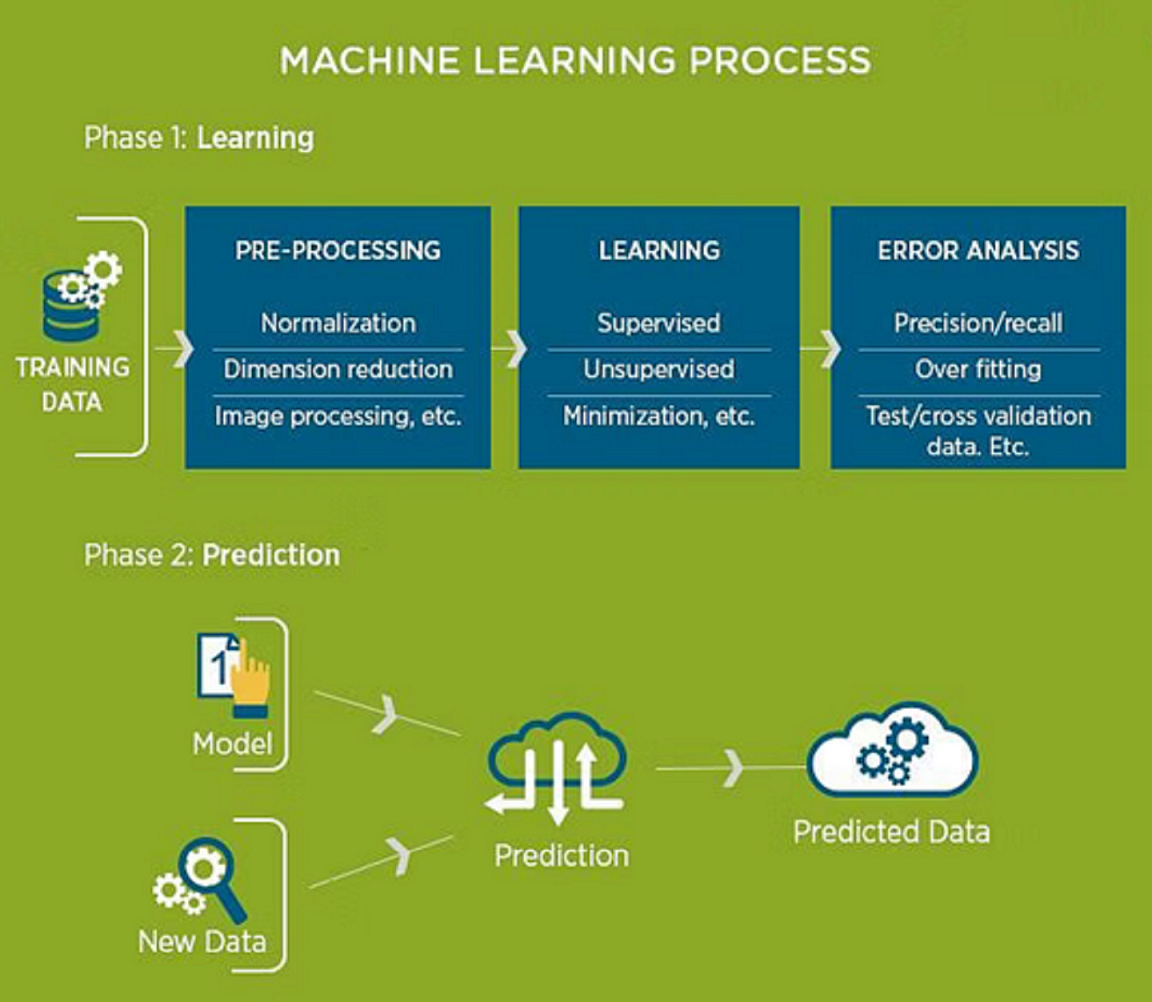
Machine Learning stands as one of the most captivating branches within Artificial Intelligence. It revolves around the process of extracting insights from data by training algorithms. Understanding the inner workings of Machine Learning not only sheds light on its functionality but also hints at its future applications.
The journey of Machine Learning commences with the input of training data into a chosen algorithm. This data, whether familiar or unfamiliar, serves as the foundation for crafting the final Machine Learning model. Notably, the nature of this training data significantly influences the algorithm, a concept we'll delve into shortly.
Subsequently, fresh data is introduced into the machine learning model to gauge its performance. The predictions generated are then juxtaposed against the actual outcomes.
In instances where disparities arise between predictions and results, the algorithm undergoes multiple rounds of re-training until the desired accuracy is achieved. This iterative process empowers the machine learning model to autonomously refine itself, progressively enhancing its predictive capabilities over time.
Exploring the Diversity of Machine Learning: What Varieties Exist?
Machine learning encompasses a rich spectrum of techniques, primarily categorised into supervised and unsupervised learning. Supervised learning involves training models with labelled data to make predictions, constituting around 70% of machine learning endeavours. On the other hand, unsupervised learning explores patterns and structures within unlabelled data, occupying approximately 10 to 20% of the field. Reinforcement learning, forming the remainder, focuses on optimising decisions through trial and error.
1. Supervised Learning: In supervised learning, we leverage labelled data to guide the training process. This guidance ensures a directed approach towards achieving successful outcomes. Through this method, input data is processed by the Machine Learning algorithm, training the model to make predictions based on the provided labels. Once trained, the model can then accurately predict outcomes for new, previously unseen data.
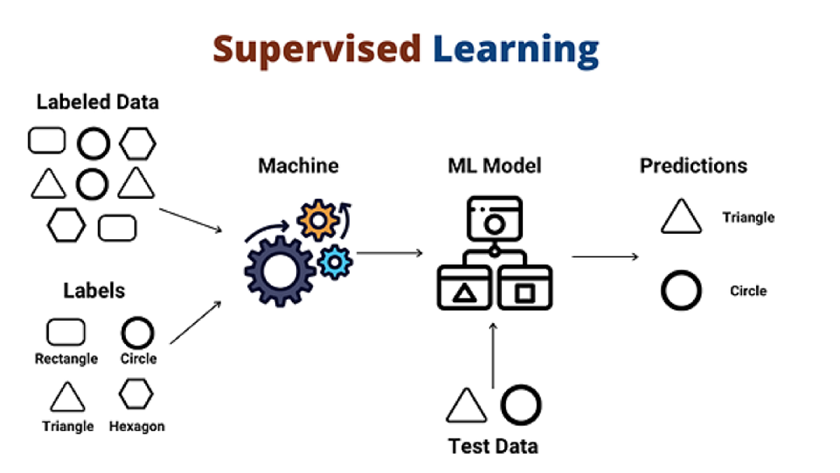
In the picture, the model tries to figure out whether the data is a circle or a triangle. Once the model has been trained well, it will identify that the data is a circle and then give the desired response.
Here are some of the leading algorithms utilised in supervised learning:
- Decision trees
- K-nearest neighbours
- Linear regression
- Logistic regression
- Naive Bayes
- Polynomial regression
- Random forest
- Support Vector Machines (SVM)
- Gradient Boosting Machines (GBM)
- Artificial Neural Networks (ANN)
- Ensemble methods (e.g., AdaBoost)
- Ridge regression
- Lasso regression
- ElasticNet regression
2. Unsupervised Learning: In unsupervised learning, the training data lacks labels, meaning it hasn't been previously analysed or categorised. This absence of guidance distinguishes unsupervised learning, as the algorithm must derive structure and patterns independently from the input. The data is fed into the machine learning algorithm for training, where the model endeavours to uncover inherent patterns without explicit instruction. This process resembles deciphering code akin to the Enigma machine, yet without direct human intervention, relying solely on machine-driven exploration and analysis.
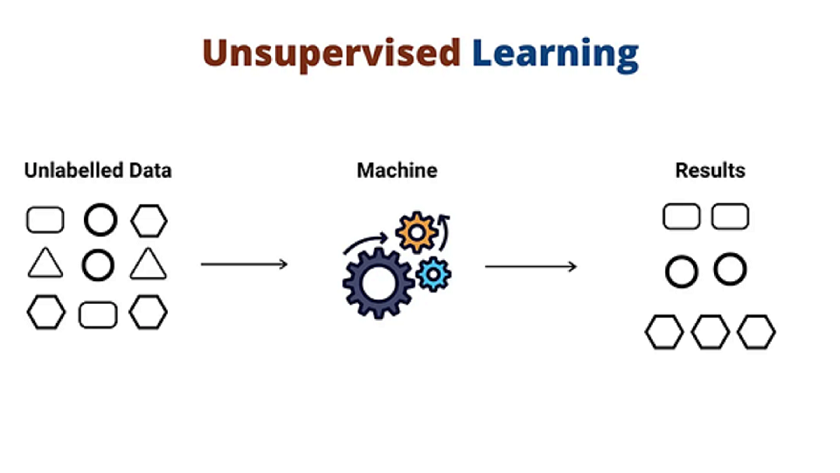
In this case, the unknown data consists of multiple shapes that look similar to one another. The trained model tries to put them all together so that you get the same things in similar groups.
The algorithms currently being used for unsupervised learning are:
a. K-means Clustering: An iterative algorithm that partitions data into k clusters based on similarity of features.
b. Hierarchical Clustering: Builds a hierarchy of clusters by either merging or splitting them based on their distance.
c. DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Clusters data points based on density, identifying core points, border points, and noise.
d. Gaussian Mixture Models (GMM): Assumes that the data is generated from a mixture of several Gaussian distributions and aims to probabilistically determine the parameters of these distributions.
e. Self-Organising Maps (SOM): Neural network algorithm that reduces the dimensionality of data while preserving its topology, often used for visualization.
f. Principal Component Analysis (PCA): Technique for dimensionality reduction that identifies the directions (principal components) that maximize variance in data.
g. Independent Component Analysis (ICA): Similar to PCA but aims to find statistically independent components rather than uncorrelated ones.
h. Anomaly Detection Algorithms: Identify outliers or anomalies in data, such as Isolation Forest and One-Class SVM.
i. Non-negative Matrix Factorization (NMF): Decomposes a non-negative matrix into the product of two lower-dimensional matrices, useful for feature extraction and dimensionality reduction.
j. Autoencoders: Neural network architecture that learns to encode input data into a lower-dimensional representation and then decode it back to the original data, often used for dimensionality reduction and feature learning.
k. Biclustering Algorithms: Simultaneously cluster rows and columns of a matrix, useful for finding subsets of data that exhibit similar behavior across both dimensions.
l. Latent Dirichlet Allocation (LDA): A generative statistical model that clusters text documents into topics based on the words they contain.
m. Spectral Clustering: Utilizes the eigenvalues of a similarity matrix to perform dimensionality reduction for clustering in fewer dimensions.
n. Mean Shift Clustering: Iteratively shifts data points towards the mode (peak) of the density function until convergence, identifying cluster centroids.
o. Density-Based Clustering Extensions: Variants of DBSCAN such as OPTICS (Ordering Points To Identify Clustering Structure) and HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise).
3. Reinforcement Learning: Similar to traditional data analysis methods, reinforcement learning involves the algorithm discovering data through trial and error to determine which actions yield the highest rewards. This process is built around three key components: the agent, the environment, and the actions. The agent serves as the learner or decision-maker, the environment encompasses everything the agent interacts with, and the actions are the steps taken by the agent.
Reinforcement learning occurs when the agent selects actions that maximize the expected reward over time. This is most effectively accomplished when the agent operates within a well-defined policy framework.
What Makes Machine Learning Essential?
To better understand "what is machine learning" and its applications, consider examples such as the self-driving Google car, cyber fraud detection, and online recommendation engines from Facebook, Netflix, and Amazon. These technologies are made possible by machines that filter relevant information and combine it based on patterns to produce accurate results.
The rapid advancements in Machine Learning (ML) have led to an increase in its use cases, demand, and overall significance in modern life. The term "Big Data" has also gained popularity in recent years, partly due to the enhanced capabilities of Machine Learning, which allow for the analysis of vast amounts of data. Machine Learning has revolutionized data extraction and interpretation by automating generic methods and algorithms, thereby supplanting traditional statistical techniques.
The rapid advancements in Machine Learning (ML) have led to an increase in its use cases, demand, and overall significance in modern life. The term "Big Data" has also gained popularity in recent years, partly due to the enhanced capabilities of Machine Learning, which allow for the analysis of vast amounts of data. Machine Learning has revolutionized data extraction and interpretation by automating generic methods and algorithms, thereby supplanting traditional statistical techniques.
Utilising Machine Learning in Diverse Applications
Machine learning offers a versatile toolkit for analysing vast amounts of data, yielding outcomes that range from personalised web search results and dynamic ad placements across digital platforms to filtering out unwanted email spam. Moreover, it's instrumental in safeguarding networks through intrusion detection and enhancing capabilities in pattern and image recognition tasks. These applications underscore the transformative power of machine learning in processing massive, diverse datasets, replacing traditional trial-and-error methods with efficient algorithms and data-driven models for swift, accurate analysis in real-time scenarios.
Choosing the Right Machine Learning Algorithm
Selecting the most suitable machine learning algorithm can be challenging due to the plethora of options available, each tailored to different scenarios. While there isn't a universal solution, several guiding questions can streamline the decision-making process:
- What is the scale of your dataset?
- What is the nature of your data?
- What specific insights do you aim to derive?
- How will these insights be applied practically?
Optimal Programming Language for Machine Learning
When considering the most favourable programming language for machine learning, Python emerges as a prominent contender due to its extensive library ecosystem and broad community support. Python excels in tasks like data analysis and mining, offering robust support for various algorithms encompassing classification, clustering, regression, dimensionality reduction, and diverse machine learning models.
Enterprise Machine Learning and MLOps
In the realm of enterprise operations, machine learning plays a pivotal role in unveiling valuable insights into customer dynamics, loyalty, and market competitiveness. Leveraging machine learning, businesses can anticipate sales trends and real-time demand, enhancing strategic decision-making.
Furthermore, Machine Learning Operations (MLOps) stands as a critical discipline in the delivery of Artificial Intelligence models. By facilitating scalable production capacities, MLOps accelerates result delivery, unlocking essential business value for organisations.
Exploring Machine Learning Algorithms and Processes
Understanding the essence of machine learning entails delving into a spectrum of standard algorithms and processes. These encompass neural networks, decision trees, random forests, association rules, sequence discovery, gradient boosting, bagging, support vector machines, self-organizing maps, k-means clustering, Bayesian networks, Gaussian mixture models, and more.
Moreover, various machine learning tools and processes leverage these algorithms to harness the full potential of big data. These encompass:
Essential Foundations for Machine Learning (ML)
Venturing beyond the fundamentals of what constitutes Machine Learning demands a solid groundwork to navigate this field effectively. Key prerequisites encompass:
- Proficiency in programming languages like Python, R, Java, JavaScript, etc.
- Intermediate grasp of statistics and probability theories.
- Fundamental understanding of linear algebra, crucial for tasks like linear regression modelling.
- Familiarity with calculus principles.
- Ability to clean and organize raw data into desired formats, expediting the decision-making process.
Meeting these prerequisites significantly enhances your prospects for a successful career in machine learning.
Same Category
- Artificial General Intelligence (AGI) 4
- Artificial Intelligence (AI) 1
- Machine Learning (ML) 1
- Autonomous Systems (AS) 1
- Natural Language Processing (NLP) 1
General Category
- Artificial General Intelligence (AGI) 8
- Robotics 5
- Algorithms & Data Structures 4
- Tech Business World 4
Sign Up to New Blog Post Alert